作者:老余捞鱼
原创不易,转载请标明出处及原作者。

写在前面的话:很多朋友觉得买了不同行业的股票就是分散风险,结果大跌时还是“全军覆没”。今天我不谈K线,直接带你用量化程序做一个“基本面+价格”的双重聚类分析。这招能帮你一眼看穿哪些股票是“穿一条裤子”的,真正做到科学避险。代码已升级为免费数据源版本,直接抄作业!
各位捞友们,大家好,我是老余。
昨晚有个粉丝在后台哭诉:“我特意买了科技股、消费股还有新能源,觉得这叫‘分散投资’,稳如老狗。结果今天大盘一跌,怎么它们手牵手一起跳水?说好的对冲呢?”
听到这儿,老余我刚喝进嘴里的枸杞茶差点喷出来。兄弟,你以为买的名字不一样就是分散投资了?你那是把鸡蛋分开放进了同一个卡车里,车翻了,蛋全碎。
在金融市场里,名字不重要,“血缘关系”才重要。很多看似不相关的股票,其实背后的资金逻辑是一模一样的。
今天,老余就结合前两天在国外量化圈很火的一篇技术贴,以及Github上最新的策略代码,带大家用“机器学习”的视角,扒一扒你手里股票的真实关系。我们要用的技术,叫股票聚类(Stock Clustering)。
01 初级玩法:看谁跟谁“穿一条裤子”
所谓的聚类,说人话就是“物以类聚,人以群分”。
想象一下,你走进一个热闹的酒吧。虽然里面有几百号人,但你仔细一看,就能分出几个圈子:

- 圈子A: 西装革履,喝着威士忌聊上市(银行金融股)。
- 圈子B: 穿着格子衫,眼镜片很厚,聊代码(科技股)。
- 圈子C: 拿着保温杯,在那儿聊养生(医药消费股)。
在股市里,我们看两个股票是不是“一伙的”,最简单的办法就是看它们的价格走势(Price Action)。
如果股票A涨,股票B也涨;A跌,B也跌,那它俩就是“好基友”,相关性很高。如果你同时重仓这两个,只要有点风吹草动,你就等着双倍酸爽吧。
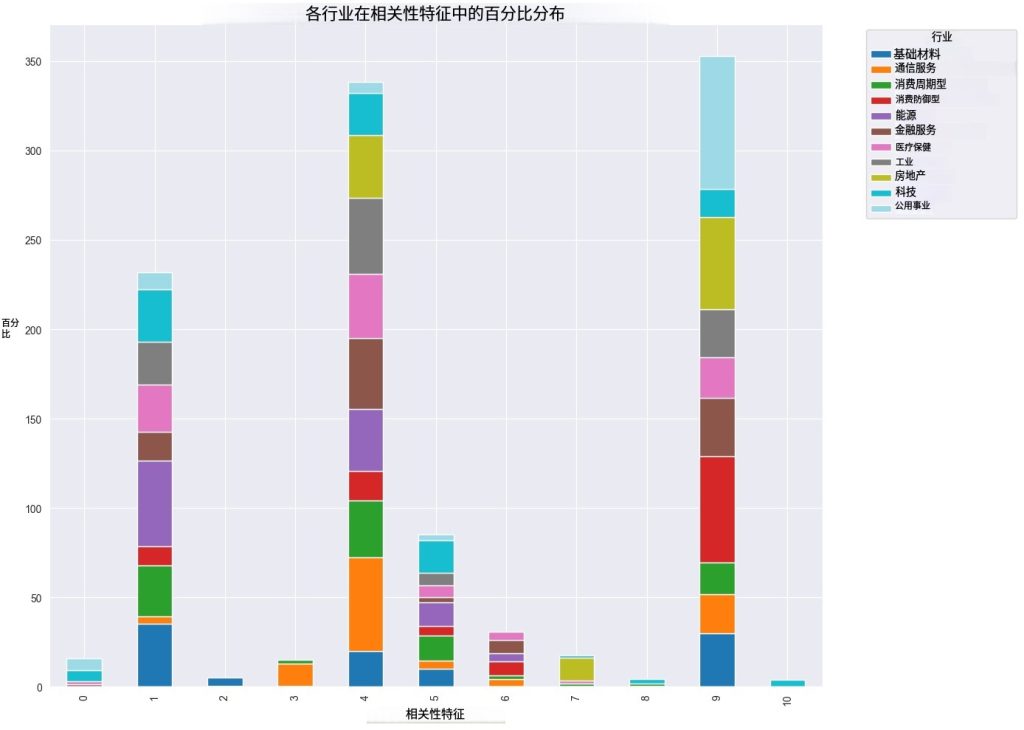
看上图,红色的区域就是“抱团区”。如果你手里的票都集中在红区,那你其实只买了一只股票。
02 进阶Pro版:给股票做“CT扫描”
“老余,光看价格走势就够了吗?”
问得好!这就涉及到了量化的第二层思维。有时候,垃圾股和绩优股在牛市里都涨,走势很像,但本质完全不同。一旦潮水退去,一个在裸泳,一个在游艇上。
所以,我们不仅要看它“怎么走”(价格),还要看它“身体好不好”(基本面)。
这里老余要引入一个更高级的概念:基本面+价格双重聚类。我们要把以下指标扔进算法的大锅里:
- 市盈率 (PE): 看它贵不贵。
- 市值 (Market Cap): 看它盘子大不大。
- 波动率 (Volatility): 看它脾气暴不暴躁。
- Beta系数: 看它跟大盘紧不紧。
但是问题来了:市盈率是几十,市值是几千亿,波动率是百分之几。这些单位都不一样,怎么比?
这时候,就要祭出我们的神器——PCA(主成分分析)。
你就把它想象成一个“超级榨汁机”。你往里面扔进去苹果(价格)、香蕉(PE)、牛奶(市值),它咔咔一顿转,把这些乱七八糟的数据“降维打击”,最后吐出来一杯纯净的混合果汁。AI喝了这杯果汁,就能精准地把股票分成三六九等。
03 手把手实战:3分钟跑出你的策略
光说不练假把式。老余把Github上的付费代码,改写成了免费版(基于yfinance)。不管你是程序员还是金融民工,复制粘贴,把这图跑出来,发个朋友圈,逼格瞬间拉满。
第一步:环境准备与数据下载
我们选取美股市场上最具代表性的几只票:科技巨头、传统防守股、能源股和银行股,看看AI能不能把它们区分开。
Step 1: Get Data (Free Source)
import yfinance as yf
import pandas as pd
import numpy as np
# 1. 定义股票池:我们故意选几个不同行业的
tickers = [
'AAPL', 'MSFT', 'NVDA', 'TSLA', 'GOOG', # 科技疯狗组
'KO', 'PEP', 'JNJ', 'MCD', 'PG', # 养老防守组
'XOM', 'CVX', 'JPM', 'BAC' # 周期蓝筹组
]
print("老余正在帮你去海外捞数据,请耐心等待...")
data_list = []
for t in tickers:
try:
stock = yf.Ticker(t)
# A. 获取基本面信息 (体检报告)
info = stock.info
# B. 获取价格历史 (计算脾气暴不暴躁)
hist = stock.history(period="1y")
# 计算年化波动率
volatility = hist['Close'].pct_change().std() * (252**0.5)
# 将关键指标装进篮子
data_list.append({
'Ticker': t,
'PE': info.get('trailingPE', 0), # 市盈率
'MarketCap': info.get('marketCap', 0), # 市值
'Beta': info.get('beta', 1), # 贝塔
'Volatility': volatility # 波动率
})
except Exception as e:
print(f"哎呀,{t} 的数据没捞到: {e}")
# 整理成表格
df = pd.DataFrame(data_list).set_index('Ticker')
df = df.fillna(0) # 填补空缺
print("数据集结完毕!")第二步:开启“榨汁机” (PCA降维与聚类)
这一步是核心。我们要把几千亿的市值和几十的市盈率放在一起比,必须先做标准化(Standardization),然后用K-Means算法把它们自动分组。
Step 2: AI Clustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import seaborn as sns
# 1. 数据标准化 (把大家拉到同一起跑线)
scaler = StandardScaler()
df_scaled = scaler.fit_transform(df)
# 2. PCA降维 (把4个指标压缩成2个主成分,方便画图)
pca = PCA(n_components=2)
principal_components = pca.fit_transform(df_scaled)
# 3. K-Means聚类 (假设我们要分4个帮派)
kmeans = KMeans(n_clusters=4, random_state=42)
df['Cluster'] = kmeans.fit_predict(df_scaled)
# 4. 把PCA的结果也存进去,方便一会儿画图
df['PC1'] = principal_components[:, 0]
df['PC2'] = principal_components[:, 1]
# 打印结果看看
print(df.sort_values('Cluster')[['Cluster', 'PE', 'Volatility']])第三步:可视化你的“股市地图”
最后,我们画一张散点图。点离得越近,说明它们越像;颜色不同,代表不同的帮派。
Step 3: Visualization
plt.figure(figsize=(10, 8))
sns.scatterplot(
x='PC1', y='PC2',
hue='Cluster',
data=df,
palette='viridis',
s=200 # 点的大小
)
# 给每个点标上名字
for i in range(df.shape[0]):
plt.text(
df.PC1[i]+0.1,
df.PC2[i]+0.1,
df.index[i],
fontdict={'size': 12}
)
plt.title('老余捞鱼 - 股票基本面+价格聚类图', fontsize=15)
plt.xlabel('主成分 1 (通常代表波动/成长性)')
plt.ylabel('主成分 2 (通常代表市值/稳健性)')
plt.grid(True)
plt.show()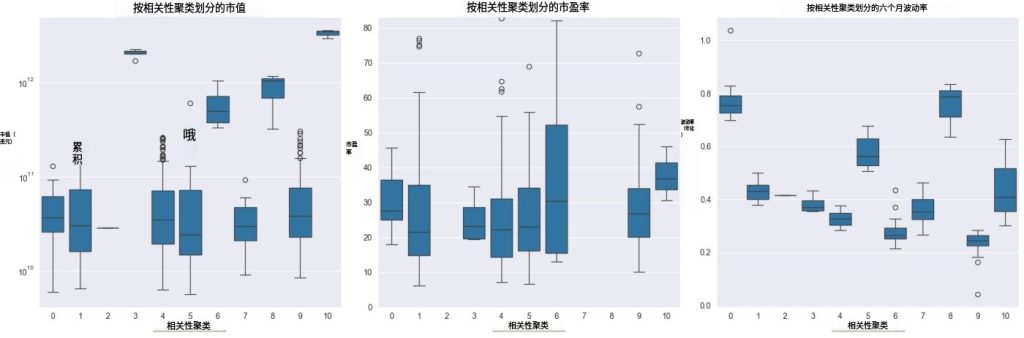
你会看到:
● 特斯拉、英伟达 在右上角(高波动、高成长)
● 可口可乐、强生 在左下角(低波动、稳健)
● 苹果、微软 在中间(兼顾成长与稳健)
04 深度解析:怎么用这个图?
图跑出来了,怎么指导我们的实盘操作?老余总结了一个对比表:
| 维度 | 小白的“伪分散” | 老余的“AI分散” |
|---|---|---|
| 持仓特征 | 全买热门股(英伟达+特斯拉+AMD) | 跨类别配置(Cluster 1 + Cluster 2 + Cluster 3) |
| 遇到加息 | 估值杀,全线崩盘,关灯吃面 | 成长股跌,但价值股(如银行能源)扛住了 |
| 心态 | 每天盯着K线心惊肉跳 | 东方不亮西方亮,稳如泰山 |
| 核心逻辑 | 赌赛道 | 数学相关性对冲 |
实战建议:
如果你的持仓里,80%的股票都挤在同一个颜色的Cluster里,哪怕它们行业不同,你的风险也是极度集中的。试着把资金分散到图表上距离最远的两个点上,那才是真正的“资产配置”。
05 观点总结
兄弟们,投资这事儿,有时候真不能光靠直觉。你觉得它们不一样,但资金流向告诉你,它们就是一回事。
今天介绍的这个基本面+价格双重聚类,是量化机构里常用的手段。它能帮你撕开股票表面的标签,看到资金流动的真相。
📝 核心笔记
- 分散≠数量多: 即使你买了10只科技股,只要它们在同一个聚类里,风险就是100%。
- 相信算法: 人脑处理不了多维度的复杂关系(PE、市值、波动率混在一起),但PCA和聚类算法可以。
- 动态调整: 市场风格会变(比如现在AI火,以前是新能源火),建议每个季度跑一次这个代码,给持仓做个“体检”。
- 工具是辅助: 量化工具帮你排雷,但选股的最终逻辑,还得看企业的基本面。
好了,今天的干货就捞到这里。代码如果有报错,或者想看A股版本(如何分析茅台和宁德时代),点赞、在看、转发三连,人数多的话老余下期专门出一期A股实战版!
我是老余,用数据说话,咱们下期见!👋
#量化交易 #Python金融 #资产配置 #老余捞鱼 #股票聚类
觉得老余这篇干货有用的,老规矩,点赞在看,评论区见! 👇
风险提示:投资有风险,入市需谨慎。本文仅供学习参考,不构成投资建议。
Be First to Comment