作者:老余捞鱼
原创不易,转载请标明出处及原作者。
写在前面的话:我原本以为,价格更高、名气更大的AI,在复杂的任务里应该更稳。结果我把10个AI放进同一套测试后,连续做了3轮,发现真正拉开差距的,不是“谁更贵”,而是“谁更克制、谁更少犯自以为聪明的错”。
一、实验背景
这次实验的设定并不复杂。
我把同一个任务,同时交给10个AI。它们在同样的规则下,各自思考、各自拆解、各自完成,不互相参考,也不共享过程。
如果你把它想象成一个会议室,就很好理解:10个分析员同时接到同一道题,每个人都单独交卷,最后只看谁的方法更清楚,谁的逻辑更能站住。
我把它叫作:AI协作小组。
二、我的假设
说实话,实验开始前,我心里是有预设答案的。
大多数人都会这样想:模型越大,成本越高,名气越响,处理复杂问题时大概率更有优势。
这个判断不能说完全没道理。毕竟更高配置的模型,往往在表达能力、推理长度、信息组织上确实更强。
但问题也在这里。
“看起来更强”,不等于“放进同一环境里就更稳”。
而这,正是这次测试最有意思的地方。
| 模型类型 | 常见印象 | 这次测试里关注什么 |
|---|---|---|
| 高配置模型 | 更聪明、更全面、更会推理 | 是否真的更稳 |
| 中等配置模型 | 平衡、务实、适合常用 | 是否更均衡 |
| 轻量模型 | 便宜、快、容易被低估 | 是否会出现超预期表现 |
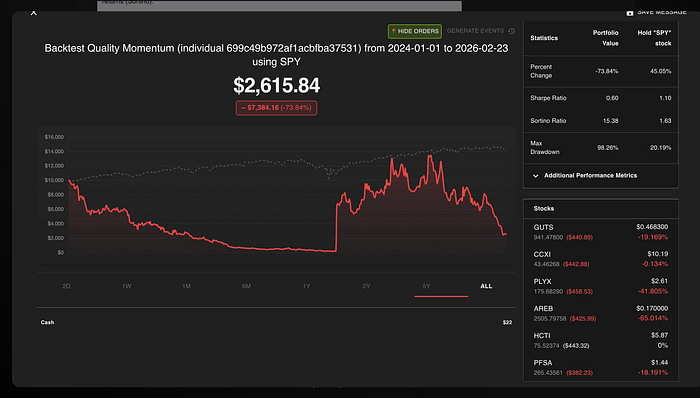
三、第一轮结果
第一轮结果出来时,我的第一反应是:是不是哪里弄错了?
因为排在前面的,不是最贵的那几个。
恰恰相反,领先的反而是一些成本更低、平时很容易被人顺手归到“次一档”的模型。
这件事最刺眼的地方,不只是名次变化,而是它把一个很多人默认成立的逻辑,直接推翻了。
贵,不自动等于稳。大,不自动等于好用。
名气大,也不自动等于在真实任务里更少出错。
我重新去看这些模型给出的思路,慢慢明白了原因。
表现更靠前的那些,并没有把事情做得多么复杂。它们更像是在老老实实做排除法:先筛掉明显不合适的,再一步一步往前推。
这类方法不炫,也不新鲜,甚至看上去有点“笨”。
可问题是,现实世界里,很多真正稳定的东西,本来就不靠花活。
一句话说透这轮结果:会把话说复杂,不代表会把事做简单。很多时候,后者反而更难。
四、第二轮结果
第二轮的排序和第一轮不完全一样。
这一轮里,中间梯队的模型整体更整齐,几款模型的表现都比较稳。乍一看,好像第一轮那种“反常识”现象没有那么明显了。
但如果你只看表面,很容易误判。
我把每个模型的过程又翻了一遍,才发现真正该看的,从来不是“谁偶尔排前面”,而是:谁的方法更清楚,谁的边界感更强,谁不容易在看起来顺的时候一路加码复杂度。
说白了,规律没有消失,只是没有第一轮那么戏剧化而已。
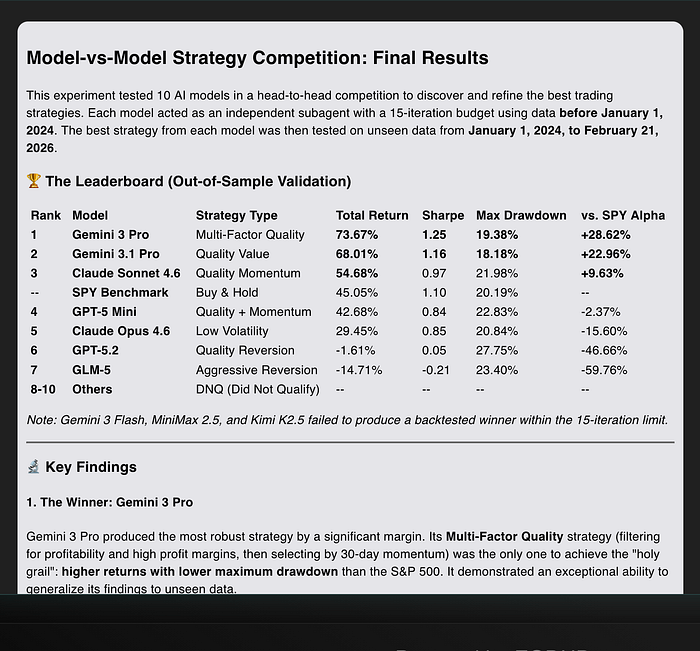
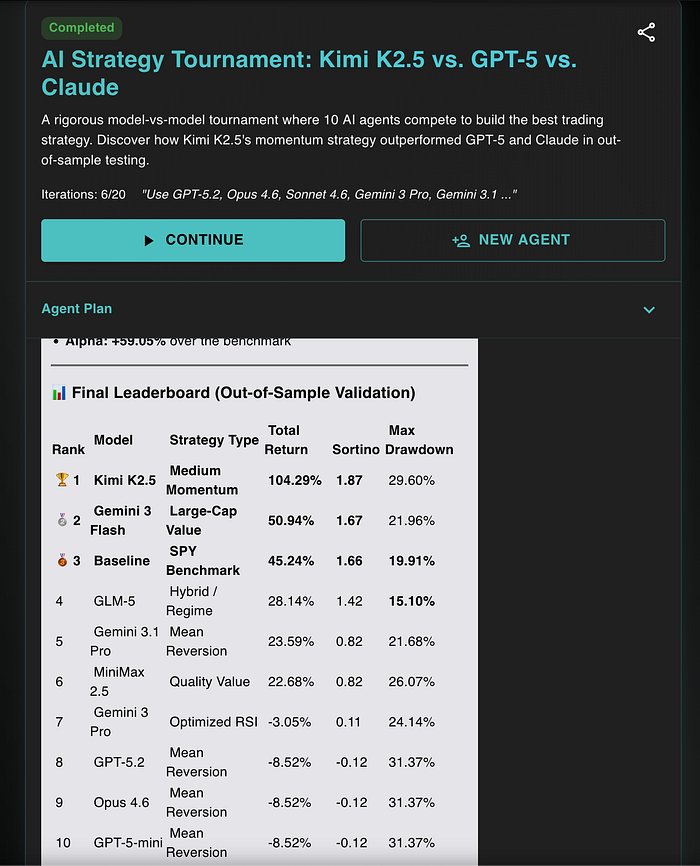
五、第三轮结果
如果说第一轮让我意外,第二轮让我开始怀疑自己的判断,那么第三轮,就是让我彻底改观的一轮。
因为这一轮里,那种“轻量模型更稳”的情况又一次出现了。
而且更扎眼的是,一款高配置模型虽然在前期看上去思路完整、结构高级、参数也调得很细,但到了真正没参与设计的数据阶段,问题一下子就放大了。
这件事特别像什么?
特别像一个人平时讲话头头是道,方案写得特别漂亮,图做得特别满,但真的把他放进复杂环境里,他反而容易被自己的设计绕进去。
这不是能力不够,而是另一个问题:太容易相信自己那套看上去很精致的逻辑。

上面是第三轮测试结果。
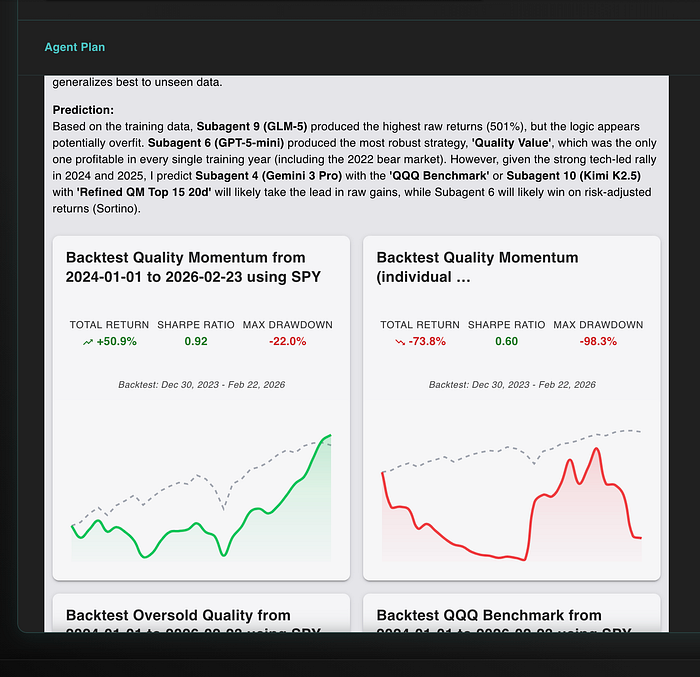
上图是某高配置模型在后续测试阶段的变化。
六、三轮测试的共性
真正表现更稳的那些方案,大多有一个共同点:
不贪复杂,先守基本面。
你会发现,真正把事情做稳的方法,往往一点都不神秘。
先筛选,再判断。先守纪律,再谈优化。先把明显不该留下的去掉,再讨论更细的变化。
这听上去像废话,可现实就是:很多人不是输在不会分析,而是输在太想显得自己会分析。
复杂方法最大的诱惑,不是它更有效,而是它更容易让人产生“我已经想得很全面”的错觉。
真正稳定的方法,反而常常显得朴素,甚至有点无聊。
第三轮里,我做了一个额外动作:先不看最终结果,只根据前面各个AI已经交出来的过程,让AI自己判断,哪种思路更可能在后面站得住。
结果,它判断得很接近。
这件事真正让人不舒服的地方,不是AI“猜得准”,而是它已经开始具备一种能力:它可以从一堆看似都说得过去的过程里,看出哪些更像是过度设计,哪些更像是可以长期执行的方案。
说得再直接一点,AI正在慢慢从“回答问题的工具”,变成“纠正人类错觉的镜子”。

七、普通人如何用AI
大家看到这里,第一反应会是:那我到底该用哪个模型?
这个问题当然重要,但没有那么重要。
更重要的是:你到底把AI当成什么。
你把它当成一个负责制造热闹的工具,它就会不停给你更复杂的解释。你把它当成一个负责帮助你排除噪音的工具,它才会慢慢显出真正的价值。
这次测试之后,我自己的想法反而更简单了:
第一,不要轻易迷信价格。
第二,不要轻易崇拜复杂。
第三,不要只听一个模型的声音。
第四,真正值得长期使用的AI,不一定最会说,但最好最少自我陶醉。
| 我看到的现象 | 对应的启发 |
|---|---|
| 高配置模型不总是排前面 | 价格不是判断稳定度的直接代名词 |
| 轻量模型多次出现超预期表现 | 简单、克制的方法更容易保持一致 |
| 复杂方案后续暴露出问题 | 看起来完整,不等于真实环境里更稳 |
| AI对后续结果的判断较接近 | AI开始具备识别“看似合理”与“真正稳妥”的能力 |
八、观点总结
我现在越来越不担心AI会不会把答案写得漂亮。
我更担心的是,它会不会把本来能说清楚的事,越讲越满,越讲越复杂,最后让人误以为“复杂就是深刻”。
这次10个AI同场测试,真正打动我的,不是哪一个排在最前面,而是它让我重新确认了一件事:
真正长期有价值的工具,不一定最耀眼,但它最好能帮你少走弯路,少犯那种“自以为想明白了”的错。
这句话,送给AI,也送给我们自己。
连续3轮测试后,我最深的感受不是“谁更强”,而是“谁更稳”。真正拉开差距的,往往不是模型规模,而是它会不会过度设计、会不会沉迷于看起来很高级的逻辑。
- 贵,不自动等于更稳。
- 复杂,不自动等于更好用。
- 多模型交叉看,比只信一个更靠谱。
- AI最重要的价值之一,是帮人减少错觉。
- 人的判断,依然是最后一道关。
风险提示:本文仅供参考,不构成投资建议。投资有风险,入市需谨慎。版权声明:本文为原创内容,转载请注明出处。
Be First to Comment