作者:老余捞鱼
原创不易,转载请标明出处及原作者。

写在前面的话:今天分享一个用Python写的LSTM模型,帮你更好地读懂盘面走势。它不是自动交易工具,而是一个实时的AI参谋:在你做决策时提供参考。代码只有80行,小白也能跑起来。
一、这不是交易机器人,是一个”第二意见”工具
今天想跟大家分享一个我最近在用的量化小工具。不是那种全自动帮你下单的机器人,而是一个实实在在的“第二意见”——每天早上给你一份分析报告,在你看盘的时候随时提供参考。
代码不长,加起来大概80行Python,但它做的事挺有意思:用LSTM模型学习过去的价格走势,然后告诉你接下来大概会怎么走。
重要提醒:这个工具输出的只是参考信息,不是交易信号。最终的决策权永远在你手里,模型只是帮你多一个视角来看问题。
二、什么是LSTM?为什么交易者需要了解它
LSTM全称是长短期记忆网络(Long Short-Term Memory),是一种专门用来处理序列数据的深度学习模型。它最厉害的地方在于:能够记住之前发生的事,并利用这些记忆来影响现在的判断。

这么说可能有点抽象,我来举个例子帮你理解:
我们平时看盘时的思考方式:
过去30分钟价格一直在缓慢下跌,在373美元附近找到了支撑。如果成交量开始放大,这里可能会反弹。
LSTM模型的”思考方式”:
根据过去60分钟的收盘价数据,结合类似的”缓跌后稳”的走势模式,模型预测下一根K线价格大概在372.71美元左右,比当前372.48美元略高。
看出区别了吗?我们人看盘靠的是经验和盘感,而LSTM靠的是它”见过”的模式。它可能不懂什么叫支撑位,但它见过足够多的类似走势,会用数字告诉你历史上这种情况通常会怎么走。
你可以把LSTM想象成一个不知疲倦的量化分析师:它一直在盯着1分钟K线图看,能告诉你类似的市场走法在过去是怎么发展的。
三、怎么把这个工具用进你的日常看盘
说完了原理,我们来聊实操。这个工具的使用流程很简单,分成三个时间节点:
盘前准备(9:00前) — 用前一天的全天数据训练模型。模型会学习过去一天的市场节奏和波动特征,大概需要2分钟在普通笔记本上跑完。
盘中决策 — 每当你在某个位置想动手之前,先看看模型的预测。它的方向跟你的判断一致吗?如果不一致,原因可能是模型看到了你没注意到的细节,也可能是模型这次判断失误了:两种情况都值得你停下来多想一想。
收盘复盘 — 对比模型今天的预测和实际走势。哪些地方它看对了?哪些地方它判断失误了?坚持记录一段时间,你会慢慢发现模型在什么市场环境下比较靠谱,在什么情况下容易出错。
四、代码实现:一步步搭起你的量化助手
接下来是技术部分,我会把代码拆成几个关键模块来讲,保证你看完不仅能跑通,还能理解每一步在做什么。
第一步:准备工具和数据
这一步主要是把需要的库导入进来,然后定义几个关键参数:
import yfinance as yfimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom datetime import datetime, timedeltafrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import LSTM, Dense, Dropout, Inputfrom tensorflow.keras.optimizers import Adamfrom sklearn.preprocessing import MinMaxScaler# === 配置参数:这几个是你需要自己调整的 ===TICKER = "TSLA" # 换成你想分析的品种LOOKBACK_INTERVALS = 60 # 用过去60根K线来预测EPOCHS = 50BATCH_SIZE = 16小提示:LOOKBACK_INTERVALS这个参数控制模型看多长的历史数据。设得越长,模型能看到更大级别的趋势,但计算量也会变大;设得短一些,模型对短期变化更敏感,但可能更容易被噪音干扰。
第二步:获取当天数据
这一步用yfinance库下载指定品种的1分钟K线数据,然后整理成一个干净的表格,只保留我们需要的价格列:
def get_processed_data(): # 下载当天的1分钟K线数据 df = yf.download(TICKER, period="1d", interval="1m", progress=False) # 处理多级列名的情况 if isinstance(df.columns, pd.MultiIndex): df.columns = df.columns.get_level_values(0) # 重命名并清理数据 df = df.reset_index().rename(columns={'Date': 'Datetime'}) df.dropna(subset=['Close'], inplace=True) return df# 获取原始数据——完整交易日的1分钟K线df_raw = get_processed_data()盘前小技巧:在把数据喂给模型之前,你可以先用 df_raw[‘Close’].describe() 看一下数据的统计特征。如果当天的波动范围明显比平时大,可能意味着今天市场比较活跃,看盘的时候要更谨慎一些。
第三步:数据归一化处理
这是很重要的一步。模型处理的数据范围太大不利于学习,所以我们把价格全部压缩到0到1之间。这个过程叫做”归一化”,就像把不同大小的水果都按比例缩小到同一个盒子里:
LOOKBACK_INTERVALS = 60 # 用过去60分钟K线来预测下一根# 初始化归一化器,将价格映射到0-1区间scaler = MinMaxScaler(feature_range=(0, 1))scaled_data = scaler.fit_transform(df_raw[['Close']])# 构建训练数据:X = 过去60个价格,y = 下一个价格X, y = [], []if len(scaled_data) < LOOKBACK_INTERVALS: print("数据量不足,跳过模型训练")else: for i in range(LOOKBACK_INTERVALS, len(scaled_data)): X.append(scaled_data[i-LOOKBACK_INTERVALS:i, 0]) y.append(scaled_data[i, 0]) # 转换为NumPy数组并调整形状 X, y = np.array(X), np.array(y) X = np.reshape(X, (X.shape[0], X.shape[1], 1)) # 80%用来训练,20%用来测试——严格按时间顺序切分 split = int(len(X) * 0.8) X_train, X_test = X[:split], X[split:] y_train, y_test = y[:split], y[split:]为什么要80/20切分?因为我们严格按照时间顺序来切分数据:前80%是较早的数据,后20%是较新的数据。这样做的好处是避免”未来数据泄露”,模型不会看到还没发生的事情。
第四步:构建LSTM神经网络
这里是模型的核心部分。两层LSTM叠加,形成”两层递进”的模式识别能力:
# 构建双层LSTM模型model = Sequential([ # 输入层 + 第一层LSTM:识别基础走势模式 Input(shape=(LOOKBACK_INTERVALS, 1)), LSTM(units=50, return_sequences=True), # Dropout层:随机断开20%连接,防止死记硬背 Dropout(0.2), # 第二层LSTM:在第一层基础上找更高层的规律 LSTM(units=50), # 输出层:给出预测价格 Dense(1)])# 编译模型:使用Adam优化器和MSE损失函数model.compile( optimizer=Adam(learning_rate=0.01), loss='mse')# 训练模型model.fit( X_train, y_train, epochs=50, batch_size=16, verbose=0)为什么要加Dropout层?
防止过度依赖:如果没有Dropout,模型可能学会”抄近道”——某一个神经元特别强,一直带着整个模型走。这样模型在新数据上表现就会变差。Dropout强迫每个神经元都得学会独立工作。
提升泛化能力:模型在”有干扰”的环境下训练过,到了真实市场(噪音更多),反而能表现得更好。
第五步:评估模型表现
模型跑完之后,我们需要知道它预测得准不准。这里用三个指标来衡量:
| 指标名称 | 含义 | 解读 |
|---|---|---|
| MSE(均方误差) | 预测误差的平方的平均值 | 对大误差惩罚更重 |
| RMSE(均方根误差) | MSE的平方根 | 跟价格单位一致,更易理解 |
| MAE(平均绝对误差) | 预测误差绝对值的平均 | 对异常值不敏感,更稳健 |
from sklearn.metrics import mean_squared_error, mean_absolute_error# 把预测结果还原成真实价格actual_test_prices = scaler.inverse_transform(y_test.reshape(-1, 1))# 计算各项误差指标mse = mean_squared_error(actual_test_prices, test_preds)rmse = np.sqrt(mse)mae = mean_absolute_error(actual_test_prices, test_preds)print(f"模型在测试集上的表现:")print(f"- 均方误差(MSE): {mse:.4f}")print(f"- 均方根误差(RMSE): {rmse:.4f}")print(f"- 平均绝对误差(MAE): {mae:.4f}")# 输出结果示例:# 模型在测试集上的表现:# - 均方误差(MSE): 0.1201# - 均方根误差(RMSE): 0.3466# - 平均绝对误差(MAE): 0.2848拿我们例子里的数字来说,MAE是0.28左右,RMSE是0.35左右。
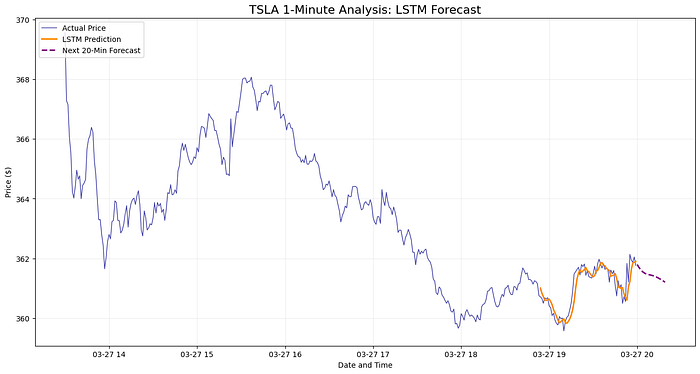
这意味着:模型预测价格跟实际价格的平均差距大概是3毛钱。
五、3倍RMSE法则:怎么过滤”噪音信号”
知道模型的误差范围之后,下一个问题就是:什么时候该信模型的预测,什么时候该忽略它?
这里有一个很实用的法则——3倍RMSE法则。只有当模型预测的波动幅度至少是RMSE三倍以上的时候,这个信号才值得重视。为什么不是看到预测涨跌就行动?原因很简单:如果模型预测价格会变动0.2美元,但它的平均误差是0.35美元,那这个”预测”其实跟掷硬币差不多。你真正应该关注的,是那些预测幅度明显超过误差范围的信号。
用数字来说明:
| RMSE倍数 | 对应波动 | 信号可信度 |
|---|---|---|
| 1倍RMSE | $0.35 | 噪音太大,等于赌运气 |
| 2倍RMSE | $0.70 | 开始有参考价值 |
| 3倍RMSE | $1.05 | 黄金标准,值得重视 |
这背后的逻辑来自统计学上的”68-95-99.7法则“(也叫正态分布三西格玛原则):
- 1σ(1倍RMSE) — 覆盖68%的数据,属于”普通”水平。
- 2σ(2倍RMSE) — 覆盖95%的数据,属于”较可信”水平。
- 3σ(3倍RMSE) — 覆盖99.7%的数据,属于”几乎确定”水平。
实战经验:真实市场还有滑点、价差、手续费这些成本。如果你每个小波动都跟着模型走,这些成本会慢慢吃掉你的账户。3倍法则帮你过滤掉噪音,只参与真正有把握的机会。
六、工具的局限性:它不是万能的
1. 趋势行情效果好,震荡行情效果差
LSTM擅长的是”延续”——延续之前的上涨或者下跌。但在横盘震荡的时候,模式会反复切换,模型的预测就会变得很不稳定。
2. 对突发消息完全无感
模型只能看到价格数据本身,如果突然出了个重大消息导致价格跳空,模型是没办法预判的。这也是为什么收盘后的复盘特别重要。
3. 只用价格数据,信息量有限
当前的版本只用了收盘价。如果加上成交量、RSI、均线这些指标,模型的判断维度会更丰富。
七、从80行代码开始你的量化之旅
今天的分享就到这里。这个工具虽然简单,但它给你打开了一扇窗:量化不是高不可攀的,80行代码就能跑起来。
如果这个工具跑了一段时间,你觉得顺手了,可以考虑在以下几个方向升级:
- 加入成交量 — 成交量的变化往往能提前反映市场情绪。
- 加入技术指标 — RSI、MACD、布林带都可以作为额外输入。
- 拉长训练窗口 — 用过去几天的数据一起训练。
- 记录每次预测的胜率 — 用Excel记下来,慢慢积累对模型的认知。
最后再强调一遍:这个工具是用来辅助你看盘的,不是替你做决定的。模型给的是概率,你做的是决策。两者结合,才是现代交易者该有的样子。
总 结
- LSTM是擅长处理时间序列的深度学习模型,能够学习价格走势中的模式。
- 该工具的核心价值在于提供客观的量化视角,与人的主观判断形成互补。
- 模型使用前需要对数据进行归一化处理,80%数据训练、20%数据测试。
- 3倍RMSE法则是实用的信号筛选标准,只有超过阈值的预测才值得重视。
- 工具可以随需求升级,加入成交量、技术指标等更多特征来丰富模型。
风险提示:本文仅供参考,不构成投资建议。投资有风险,入市需谨慎。版权声明:本文为原创内容,转载请注明出处。
#LSTM模型 #量化交易入门 #Python量化 #日内交易策略 #机器学习交易 #交易信号分析 #量化工具分享 #Python代码教学 #金融科技 #交易辅助工具
Be First to Comment